The Chain Rule
Today we get another rule for manipulating derivatives. Along the way we’ll see another way of viewing the definition of the derivative which will come in handy in the future.
Okay, we defined the derivative of the function 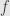 at the point
at the point  as the limit of the difference quotient:
as the limit of the difference quotient:
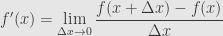
The point of the derivative-as-limit-of-difference-quotient is that if we adjust our input by 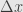 , we adjust our output “to first order” by
, we adjust our output “to first order” by 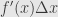 . That is, the the change in output is roughly the change in input times the derivative, and we have a good idea of how to control the error:
. That is, the the change in output is roughly the change in input times the derivative, and we have a good idea of how to control the error:
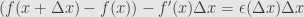
where  is a function of satisfying
is a function of satisfying  . This means the difference between the actual change in output and the change predicted by the derivative not only goes to zero as we look closer and closer to , but it goes to zero fast enough that we can divide it by and still it goes to zero. (Does that make sense?)
. This means the difference between the actual change in output and the change predicted by the derivative not only goes to zero as we look closer and closer to , but it goes to zero fast enough that we can divide it by and still it goes to zero. (Does that make sense?)
Okay, so now we can use this viewpoint on the derivative to look at what happens when we follow one function by another. We want to consider the composite function 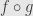 at the point
at the point  where is differentiable. We’re also going to assume that
where is differentiable. We’re also going to assume that 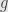 is differentiable at the point
is differentiable at the point 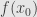 . The differentiability of at tells us that
. The differentiability of at tells us that
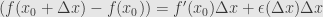
and the differentiability of at 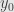 tells us that
tells us that
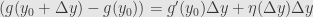
where 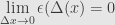 , and similarly for
, and similarly for 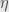 . Now when we compose the functions and we set
. Now when we compose the functions and we set  , and
, and  is exactly the value described in the first line! That is,
is exactly the value described in the first line! That is,
-\left[f\circ g\right](x_0)=g(f(x_0)+f'(x_0)\Delta x+\epsilon(\Delta x))-g(f(x_0))=](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5Bf%5Ccirc+g%5Cright%5D%28x_0%2B%5CDelta+x%29-%5Cleft%5Bf%5Ccirc+g%5Cright%5D%28x_0%29%3Dg%28f%28x_0%29%2Bf%27%28x_0%29%5CDelta+x%2B%5Cepsilon%28%5CDelta+x%29%29-g%28f%28x_0%29%29%3D&bg=e6e6e6&fg=333333&s=0&c=20201002)
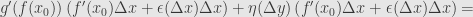
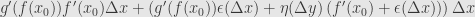
The last quantity in parentheses which we multiply by goes to zero as does. First, 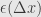 does by assumption. Then as goes to zero, so does , since must be continuous. Thus
does by assumption. Then as goes to zero, so does , since must be continuous. Thus 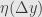 must go to zero, and the whole quantity is then zero in the limit. This establishes that not only is differentiable at , but that its derivative there is
must go to zero, and the whole quantity is then zero in the limit. This establishes that not only is differentiable at , but that its derivative there is
![\displaystyle\left[f\circ g\right]'(x_0)=\frac{d}{dx}g(f(x))\bigg|_{x=x_0}=g'(f(x_0))f'(x_0)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cleft%5Bf%5Ccirc+g%5Cright%5D%27%28x_0%29%3D%5Cfrac%7Bd%7D%7Bdx%7Dg%28f%28x%29%29%5Cbigg%7C_%7Bx%3Dx_0%7D%3Dg%27%28f%28x_0%29%29f%27%28x_0%29&bg=e6e6e6&fg=333333&s=0&c=20201002)
This means that since “to first order” we get the change in the output of by multiplying the change in its input by  , and “to first order” we get the change in the output of by multiplying the change in its input by
, and “to first order” we get the change in the output of by multiplying the change in its input by  , we get the change in the output of their composite by multiplying first by and then by
, we get the change in the output of their composite by multiplying first by and then by  .
.
Another way we often write the chain rule is by setting 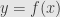 and
and  . Then the derivative
. Then the derivative  is written
is written 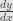 , while
, while  is written
is written 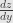 . The chain rule then says:
. The chain rule then says:
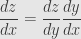
This is nice since it looks like we’re multiplying fractions. The drawback is that we have to remember in our heads where to evaluate each derivative.
Now we can take this rule and use it to find the derivative of the inverse of an invertible function . More specifically, if a function is one-to-one in some neighborhood of a point , we can find another function 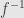 whose domain is the set of values takes — the range of — and so that
whose domain is the set of values takes — the range of — and so that  . Then if the function is differentiable at and the derivative is not zero, the inverse function will be differentiable, with a derivative we will calculate.
. Then if the function is differentiable at and the derivative is not zero, the inverse function will be differentiable, with a derivative we will calculate.
First we set and  . Then we take the derivative of the defining equation of the inverse to get
. Then we take the derivative of the defining equation of the inverse to get 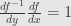 , which we could write even more suggestively as
, which we could write even more suggestively as 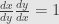 . That is, the derivative of the composition inverse of our function is the multiplicative inverse of the derivative. But as we noted above, we have to remember where to evaluate everything. So let’s do it again in the other notation.
. That is, the derivative of the composition inverse of our function is the multiplicative inverse of the derivative. But as we noted above, we have to remember where to evaluate everything. So let’s do it again in the other notation.
Since 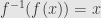 , we differentiate to find
, we differentiate to find ![\left[f^{-1}\right]'(f(x))f'(x)=1](https://s0.wp.com/latex.php?latex=%5Cleft%5Bf%5E%7B-1%7D%5Cright%5D%27%28f%28x%29%29f%27%28x%29%3D1&bg=e6e6e6&fg=333333&s=0&c=20201002) . Then we substitute and juggle some algebra to write
. Then we substitute and juggle some algebra to write
![\displaystyle\left[f^{-1}\right]'(y)=\frac{1}{f'(f^{-1}(y))}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cleft%5Bf%5E%7B-1%7D%5Cright%5D%27%28y%29%3D%5Cfrac%7B1%7D%7Bf%27%28f%5E%7B-1%7D%28y%29%29%7D&bg=e6e6e6&fg=333333&s=0&c=20201002)
December 27, 2007 -
Posted by John Armstrong |
Analysis, Calculus


[…] push away to the point . There we find a difference of . But we saw this already in the lead-up to the chain rule! This is the function , where . That is, not only does the difference go to zero — the line […]
Pingback by The Geometric Meaning of the Derivative « The Unapologetic Mathematician | December 28, 2007 |
I will admit that couldn’t understand much of it. 😀
Well the important bit is the formula in the middle that tells how to find the derivative of the composite. Above that is just making sure we have the right answer, and below that we’re just spinning off a side result about inverse functions.
It might help to say a little, too, on what John’s argument is intended to improve upon. There’s a somewhat fallacious line of reasoning that would say that the derivative of the composite function which sends x to f(g(x)) can be computed as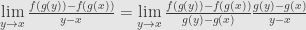 , and noting that as y approaches x, g(y) approaches g(x), so that the limit of the first factor is the derivative of f evaluated at g(x), and the limit of the second factor is the derivative of g at x.
, and noting that as y approaches x, g(y) approaches g(x), so that the limit of the first factor is the derivative of f evaluated at g(x), and the limit of the second factor is the derivative of g at x.
One trouble with this informal argument though is that g(y) might equal g(x) infinitely often as y approaches x, so that the first factor may involve illegal division by 0 infinitely often, as y moves toward x. From one point of view, John’s argument is a clever way around that objection.
But from a deeper point of view, John’s argument is emphasizing the role of the derivative f'(x) in giving the best linear approximation to a function f at a point x: the so-called “slope” m = f'(x) gives, to a first order of approximation, the expansion or dilation factor involved in passing from a small directed line segment![\left[x, x+\Delta x\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5Bx%2C+x%2B%5CDelta+x%5Cright%5D&bg=e6e6e6&fg=333333&s=0&c=20201002) to the corresponding segment from
to the corresponding segment from  to
to  .
.
The point of the chain rule is that when you first apply g and then apply f, you apply one rate of expansion and then another: that means the expansion rates get multiplied. The only thing you have to be careful about is to specify the points where the expansion rates are computed. If you start off at x and apply g, you first apply the expansion rate g'(x). If you then pick up where you left off, g(x), the expansion rate of f there is f'(g(x)). So the expansion rate at x of the composite “g followed by f” is g'(x) times f'(g(x)). That’s the chain rule.
In multivariate calculus, the multidimensional analogue of “expansion rate” is not just a number but a matrix, or better yet, a “linear transformation” which describes, to a first order of approximation, what f does to a small parallelpiped based at x (as opposed to just a small line segment based at x). The chain rule holds in higher dimensions; the slogan is “matrices multiply” (just as in the ordinary chain rule).
exactly right, Todd (given a few LaTeX tweaks). The post was a bit long to get into the tempting-but-wrong approach.
Naturally I’ll be doing the matrices and emphasizing the operator nature of the derivative (more explicitly) when I get to multiple variables. And of course I’ll get to whip out the old f-word.
If you look at diferentiation as division in a certain class of functions (say, continuous ones), the chain rule bocomes obvious. See my web page at http://www.mathfoolery.org and especially a short summary of treating calculus via algebra and uniform estimates at http://www.mathfoolery.org/talk-2004.pdf
I like this web site and would like to put some of my stuff on it. It looks like it’s easy to unclude LaTex formatted material here.
Michael, that works to give an idea of how to think about some of the differentiation rules, but the rubric of quotients doesn’t work at all once we move to multi-variable functions. The chain rule, in particular, looks a lot less like multiplying fractions.
As for the site as a whole. Do you mean WordPress, or my own weblog in particular. If it’s the latter you mean, I’m sorry but I’m not looking to co-host. It’s easy enough to get a free WordPress hosted weblog, though, as many mathematicians and students already have.
I guess I meant WordPress, although your blog is not bad either. As for the chain rule, in many variables we can look at differentiation as linear approximation, i.e., the estimate where
where 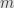 is some modulus of continuity. That will work.
is some modulus of continuity. That will work.
Yes, that’s another definition, but it’s still not really a “division” as you asserted.
I initially asserted nothing for many variables, it was your idea. Division works great for 1 variable, you must admit. is differentiable in direction
is differentiable in direction 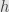 if
if 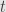 divides
divides  in a reasonable function ring (or module). In a sense, differentiable functions a those that take their values in a neat way, as polynomials do. One more example, with 2nd order partial:
in a reasonable function ring (or module). In a sense, differentiable functions a those that take their values in a neat way, as polynomials do. One more example, with 2nd order partial:
 vanishes for
vanishes for 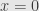 and
and  , so, if
, so, if 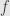 is nice it must be divisible by
is nice it must be divisible by 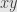 , and the value of the fraction
, and the value of the fraction  at
at  is just
is just 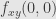 . When we work with the ring of continuous functions we recapture the classical analysis. So, differentiation cam be reduced to division.
. When we work with the ring of continuous functions we recapture the classical analysis. So, differentiation cam be reduced to division.
But if you insist on division in many variables, you can do it too, say, for partial or directional derivatives, by saying that
Division works as a mnemonic, but in the long run thinking of differentiation as division is harmful to a student because that viewpoint very much does not generalize.
Yes it does, want to differentiate a distribution? Just divide by
by  and evaluate at
and evaluate at  . Besides being generalizable and rigorous, division is totally elementary for polynomials and is nice stepping stone to classical analysis if the student wants to study it. There are already plenty of definitions of differentiation, viewing it algebraically is a nice unifying idea that simplifies the whole area. When you learn something new, it is better to start with simple examples to get going and motivated, the abstractions and generalities can wait. Also once you derive the differentiation rules for polynomials, you don’t have to unlearn them since they extend to continuously differentiable functions by continuity because any continuous function can be approximated by polynomials. To the approach via algebra and uniform estimates is even better for the future math majors since it is closer to modern mathematical ideas. It’s a bit unusual, but I’m sure you will like it once you try it. It allows to present most of the subject in a bunch of problem sets that students can handle and enjoy.
. Besides being generalizable and rigorous, division is totally elementary for polynomials and is nice stepping stone to classical analysis if the student wants to study it. There are already plenty of definitions of differentiation, viewing it algebraically is a nice unifying idea that simplifies the whole area. When you learn something new, it is better to start with simple examples to get going and motivated, the abstractions and generalities can wait. Also once you derive the differentiation rules for polynomials, you don’t have to unlearn them since they extend to continuously differentiable functions by continuity because any continuous function can be approximated by polynomials. To the approach via algebra and uniform estimates is even better for the future math majors since it is closer to modern mathematical ideas. It’s a bit unusual, but I’m sure you will like it once you try it. It allows to present most of the subject in a bunch of problem sets that students can handle and enjoy.
Michael, I’m sorry but I just disagree here.
Hey, that’s O.K. at least you have an opinion 🙂
But I still hope you will take a look at
http://www.mathfoolery.org/talk-2004.pdf and
http://www.ams.org/bull/2007-44-04/S0273-0979-07-01174-3/home.html
and see how much simpler everything becomes before you make up you mind. There is also a book by a Chinese mathematician on the way: http://www.fetchbook.info/fwd_description/search_9789812704597.html
Again, the notion of “divison” provides a useful temporary way of thinking about differentiation, but a derivative is not a quotient, and I see students forced to unlearn exactly that crutch all the time. In the end, I think it does more harm than good because the average calculus student simply doesn’t understand the subtlety of exactly where it’s a valid analogy and where it isn’t.
But if you deal with continuous functions, classical differentiation IS division. See, for example, page 4 of Weyl’s Classical Groups, their Invariants and Representations or page 236 of Analysis by Its Historey (Caratheodory formulation). It is not an analogy, it’s a fully legitimate approach, can’t you see?
No, it’s not division, but it plays division on TV. Mathematicians spent a century working out the concept of topology and limit precisely to make rigorous sense of this intuitive concept. Why did they have to do all that work? Because it fails at the edges.
Seriously, I’m getting very tired of discussing this.
And if you are so much against division, you can use uniform differentiability right away, like Hermann Karcher from Bonn University did and Peter Las did in his calculus book,
http://www.fetchbook.info/fwd_description/search_9780387901794.html
Arguing what a derivative Is is rather naive, we should think instead about what approach to differentiation is simpler and and easier to understand, and in my opinion algebra and uniform estimates win hands down, especially if we are concerned with practical and applied parts of the subject.
So go ahead and teach it that way. I disagree, and I’ve said that over and over and over. What, precisely, do you want from me?
But you are not even discussing it, you just resist your dogmas to be questioned, acting like a true believer, I’m sorry to say.
I don’t want anything from you, I just wanted to share some ideas with you, hoping that you would find them interesting. Sorry for annoying you.
I’m not discussing it because I’ve had this discussion. And I’ve had it over and over and over again. And I’ve nursemaided student after student after student past the pitfalls where the intuition breaks down. I’m sick and tired of it.
You have your own reasons for loving your approach, but I simply disagree. In my experience my own pedagogical approach communicates the concepts well enough. I tell students that thinking of division can help as a mnemonic, but can mislead you if taken too seriously, and I try to keep them ready to understand gradients and other more advanced derivatives when they come up later.
Besides which, I’ve even been rather explicit in this weblog itself that I consider, for example and
and 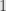 to be different functions because the former is undefined at
to be different functions because the former is undefined at 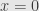 . You seem to say that the two are the same function, while I have my reasons for keeping them separate, if closely related.
. You seem to say that the two are the same function, while I have my reasons for keeping them separate, if closely related.
But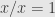 in the ring of polynomials and in the ring of continuous functions that’s exactly the point!
in the ring of polynomials and in the ring of continuous functions that’s exactly the point!
Look, instead of prohibiting the students from using algebra, i.e. synplify-and-plug-in and forcing them into using limits that are usually not well explined and difficult to understand, aren’t we better off explaining them why their simple-minded approach works? When we divide functions, we usually divide their expressions, not the individual values.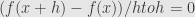 by continuity, it’s just a special case of division, we can use some other class of functions as well, such as polynomials, Lipschitz, etc.
by continuity, it’s just a special case of division, we can use some other class of functions as well, such as polynomials, Lipschitz, etc.
There is no contradiction here, when we take a limit, we simply extend
No, they’re not the same in the ring of continuous functions, because they have different domains. You’re thinking of some fuzzily-defined “ring”, where I’m looking at the sheaf of rings. The function is just not defined at
is just not defined at 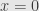 , though we have standard ways of talking around that problem. I even went through this in the link I gave.
, though we have standard ways of talking around that problem. I even went through this in the link I gave.
What you’re advocating is exactly what mathematicians have been fighting against for decades. It’s called “algebrizing the calculus”, and the debate’s been done to death.
Again, you’re free to advocate whatever position you want to your own students and in your own expositions, but I’ve looked at this before. I’m not interested in discussing it because I’ve looked at it so many times. You’re not telling me anything I haven’t already seen, and then you complain that I don’t take you seriously. Go, spread your gospel to someone who wants to hear it. I’m not buying.
Come on, polynomials, continuous functions, Lipschitz functions are rings, without qutation makrs, by the way, and not at all fuzzy, and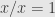 in these rings, what is wrong with you? Why are you offended? Because I question your understanding of the subject you assume you know all about? As for buying, you don’t have to, the product is free.
in these rings, what is wrong with you? Why are you offended? Because I question your understanding of the subject you assume you know all about? As for buying, you don’t have to, the product is free.
Let me make it clear, when I say that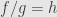 I mean
I mean  , no need for sheafs here, rings of functions sre enough. Of course, the catch is that we deal only with functions of a certain class, say continuous. If you look at it this way, calculus becomes an algebraic theory. I don’t understand why you find it so offensive, calculus is just a part of algebra of functions.
, no need for sheafs here, rings of functions sre enough. Of course, the catch is that we deal only with functions of a certain class, say continuous. If you look at it this way, calculus becomes an algebraic theory. I don’t understand why you find it so offensive, calculus is just a part of algebra of functions.
Sorry, the king has no clothes, calculus is an algebraic theory, I hope you will get over it.
Functions on what domain? You keep leaving that bit out. You can’t divide by in the ring of continuous functions on
in the ring of continuous functions on  .
.
You sweep topological and analytic considerations into the word “continuous” and then declare that they don’t exist, leaving calculus as some purely algebraic theory, when it simply isn’t. There are large swaths of it which can be dealt with algebraically, but there are parts that can’t. What about a function for which we have no formula? A black-box we can’t tinker with the insides? We can’t algebraically manipulate it, but we can still take limits, and we can still do calculus with it.
I’m not offended. I just disagree with your opinion on whether this is a valuable pedagogical viewpoint or not. And I’ve said that over and over again, and you keep screaming back. What do you want?
Sorry to butt in, but can I offer some points of view?
It sounds like Michael is arguing that for many of the typical functions f encountered in (1-dimensional) calculus, it’s more or less harmless to speak of a globally defined quotient (f(x)-f(a))/(x-a), insofar as a singularity at x = a is obviously removable. For example, for polynomials f, it’s obvious (e.g., by finite geometric series) that x-a divides f(x)-f(a). In part, John is arguing back that to make the notion of removable singularity rigorous, one needs at least some analysis. I can see some merit in each of these points, and I’d be surprised if John and Michael didn’t (I think there are larger points in the background, but I’ll get to those.)
For example, I think it’s reasonable to argue that when teaching calculus to beginners, it can definitely be a distraction to harp on limits too much — for one thing, the definition is not easy to fully grasp at first. It sounds like Michael is saying that when teaching the derivative of say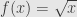 from first principles, there really is a sense in which the singularity at x = a of (f(x)-f(a)/(x-a) is obviously removable after a short algebraic manipulation, so why make heavy weather over limits here? In more sophisticated applications, one may have to calculate some estimates and establish some Lipschitz constants before it becomes “obvious” (in the same sense) that a singularity is removable, but in practice this hope is often fulfilled. So, to put it jokily, in practice limits are frequently “removable singularities” — and maybe there’s some good pedagogy there.
from first principles, there really is a sense in which the singularity at x = a of (f(x)-f(a)/(x-a) is obviously removable after a short algebraic manipulation, so why make heavy weather over limits here? In more sophisticated applications, one may have to calculate some estimates and establish some Lipschitz constants before it becomes “obvious” (in the same sense) that a singularity is removable, but in practice this hope is often fulfilled. So, to put it jokily, in practice limits are frequently “removable singularities” — and maybe there’s some good pedagogy there.
But, to do the mathematics honestly and in greater generality (thinking here especially of situations in which one can’t establish suitable uniform bounds or Lipschitz constants), John would be right that in order to make the notion of removable singularity fully rigorous, one has to deal with limits (I am ignoring for now something like nonstandard analysis, which is a whole other kettle of fish). Insofar as John is trying to tell an honest story on his blath — a story with a long and distinguished history behind it as we know — I think his reaction is quite understandable.
So, (sorry, Michael): I think it’s overshooting to baldly assert that calculus is an algebraic theory, although I think we can all agree [and John did say] that certainly huge chunks of it are algebraizable, and usefully so (for example, one can [and wants to] do differential calculus in algebraic geometry), and that there are at least some advantages to taking that POV.
Regarding the derivative as a quotient: it is definitely arguable that that should be downplayed when teaching multidimensional calculus. There is such a thing as the derivative of a function f: R^m –> R^n, which returns a linear transformation at each point where it is defined, and I can remember being confused about this when I was younger, thinking that it should involve division of vectors. Of course, one doesn’t divide by vectors. Perhaps one can take the POV that such “derivatives” involve matrices of partial derivatives, which brings us back to the 1-dimensional case discussed above, but this is a kind of reductionism which for one thing doesn’t do justice to a coordinate-free approach. I don’t think there’s any really useful way to think of such higher-dimensional derivatives as difference quotients.
Let me address John’s objections first. Let’s take a look at division by in the ring of polynomials on
in the ring of polynomials on  . Only the polynomials that vanish at 0 are divisible by
. Only the polynomials that vanish at 0 are divisible by  . But for any polynomial
. But for any polynomial 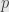
 is divisible by
is divisible by  (long division) and we can write
(long division) and we can write 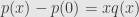 and define
and define 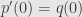 . Likewise, not all Lipschitz functions on
. Likewise, not all Lipschitz functions on  are divisible by
are divisible by  , but some are. If
, but some are. If  divides
divides  we can write
we can write 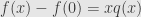 and define
and define 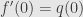 . See the analogy? Substitute “continuous” for “Lipschitz”, and you will get classical differentiability. Instead of Lipschiz we can use any modulus of continuity (and any continuous function has one), for example,
. See the analogy? Substitute “continuous” for “Lipschitz”, and you will get classical differentiability. Instead of Lipschiz we can use any modulus of continuity (and any continuous function has one), for example, 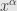 . So, by using this algebraic approach, we are not missing any of the classical theory. Differentiability of
. So, by using this algebraic approach, we are not missing any of the classical theory. Differentiability of 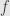 at
at  is the same as divisibility of
is the same as divisibility of  by
by  , in this respect differentiable functions behave like polynomials. Now, all polynomials are Lipschitz (long division again), so the Lipschitz theory is simply a generalization of the polynomial theory. See how it flows, from special to general, from examples to definitions, from observations and calculations to theorems, all the way using the tools familiar to the students? Isn’t it better than clubbering them with the abstractions they are not ready for (for every epsilon there is delta such that for every x… and what “is” is, as Bill Clinton had put it aptly?) or invoking “intuition” to describe the general notion of continuity that is so terribly remote from intuition?
, in this respect differentiable functions behave like polynomials. Now, all polynomials are Lipschitz (long division again), so the Lipschitz theory is simply a generalization of the polynomial theory. See how it flows, from special to general, from examples to definitions, from observations and calculations to theorems, all the way using the tools familiar to the students? Isn’t it better than clubbering them with the abstractions they are not ready for (for every epsilon there is delta such that for every x… and what “is” is, as Bill Clinton had put it aptly?) or invoking “intuition” to describe the general notion of continuity that is so terribly remote from intuition?
But onward with the Lipschitz theory! Take a look at the factoring: . Here
. Here 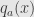 is Lipschitz, in particular,
is Lipschitz, in particular, 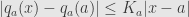 with some constant
with some constant 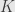 . Let’s plug this inequality in and use our definition
. Let’s plug this inequality in and use our definition  latex |f(x)-f(a)-f'(a)(x-a)| \leq K_a(x-a)^2$. Now, the dependence of
latex |f(x)-f(a)-f'(a)(x-a)| \leq K_a(x-a)^2$. Now, the dependence of 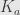 on
on  may be rather nasty in general, and in the most favorable (and practical) situation, when
may be rather nasty in general, and in the most favorable (and practical) situation, when  is Lipschitz,
is Lipschitz, 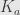 will be bounded, and the estimate will be uniform:
will be bounded, and the estimate will be uniform:  . We can take this estimate as the definition of the uniform Lipschitz differentiability (ULD), and see immediately (by dividing the inequality by
. We can take this estimate as the definition of the uniform Lipschitz differentiability (ULD), and see immediately (by dividing the inequality by  , switching
, switching  and
and  and comparing these inequalities) that
and comparing these inequalities) that 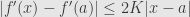 , i.e.,
, i.e.,  is Lipschitz. See the analogy with the polynomials? The derivatives of polynomials are polynomials, the derivatives of ULD functions are Lipschiz. The inequality defining ULD can be arrived at when we examine polynomials and try to understand why a tangent looks like a tangent and why polynomials with positive derivatives are increasing. This monotonicity theorem takes the center stage in the uniform approac to calculus. Again, the flow of material is from examples to definitions, from special to general, from problems to theorems. It reflects better how the mathematical notions are discovered and evolve naturally. Now, instead of Lipschitz we can use any modulus of continuity, and recapture uniform differentiability in the classical sense, see a nice article by Mark Bridger at
is Lipschitz. See the analogy with the polynomials? The derivatives of polynomials are polynomials, the derivatives of ULD functions are Lipschiz. The inequality defining ULD can be arrived at when we examine polynomials and try to understand why a tangent looks like a tangent and why polynomials with positive derivatives are increasing. This monotonicity theorem takes the center stage in the uniform approac to calculus. Again, the flow of material is from examples to definitions, from special to general, from problems to theorems. It reflects better how the mathematical notions are discovered and evolve naturally. Now, instead of Lipschitz we can use any modulus of continuity, and recapture uniform differentiability in the classical sense, see a nice article by Mark Bridger at
http://www.math.neu.edu/~bridger/LBC/lbcswp.pdf for a nice exposition. As he says in this article, lots of theorems proofs in anlysis start with: “the function is continuous, therefore it’s uniformly continuous,” so, why not start with uniform continuity and differentiafility right off the bat?
Now, John, for your question “on what domain?” When we work with uniform estimates the question of domain becomes immaterial, since any uniformly continuous, or Lipschiz function automatically extends to the completion of its original domain. We can start with rational numbers, or algebraic numbers, or any other dense subset of the interval, it doesn’t matter, the results will be the same.
And frankly, we don’t even need the reals in the full generality in this approach, the subtle notions of compactness and completeness play almost no role in it. About the only thing that we need is the Archimedes axiom: any number that is less than any negative number is either zero or positive.
Now, about topological and analytic considerations. I never claimed that they don’t exist, but I claim that in an introductory calculus such considerations are better handled by explicit uniform estimates. I think that dragging in the generalities and clubbering students with terminology at this stage is counterproductive. Continuity and limits can be introduced later (or in a different course of introductory analysis), and will look more natural to those who saw the uniform estimates.
What about a function that have no formula? It’s fine, it has some other description (it may be a solution to a differential equation) or properties (it may be Lipschitz, or integrable, ect.). The box is not usually totally black, otherwise we can’t say anything. How can you take a limit of a totally black box function? You can just dream about it, that’s about it. We usually have some estimates or other properties to work with.
Surely, neither naive algebraic nor uniform estimates approach work universally, but neither the classical approach breaks down too when we move to measures and other distributions, and there the algebraic and absract point of view shows us the way forward. There is nothing sacred about our definitions, they just codify the situations that we encounter when we try to solve this problem or that, the idea that there is THE DEFINITION for everythig is a fallacy. The only mesure of the value of a definition is how useful it is in solving problems.
Now about pedagogy. When you teach physics, do you start with quantum field theory or general relativity? Surely not, you start with some simple mechanics, conceptual parts of heat, electricity etc. You treat elementary problems by elementary means. You don’t drag in the advanced notions when the simple notions do the job. Why not do the same with introductory calculus? Why use complicated explanations and advanced tools when simple tools do the job and simple explanations are available? Just compare the complexity new approach that I (and other people) are suggesting with complexity of the classical analysis and see the difference. You can actually explain in all the details the new approach to a student who mastered high school algebra and geometry, with very little overhead. Can you do the same for classical approach? I seriously doubt it.
See? I’m not screaming, I wanted you to take a look and you didn’t want to see, it was you who kept screaming. What do I want? I want to shake you out of your complacency, I want you to stop hiding behind the memorized abstractions and take a fresh look at the subject you are teaching. I want you to recognize a promising idea when you see it, even if it’s an unusual one and you knee-jerk reaction is just to brush it away.
Now for you, Todd, and I’m glad you have joined our discussion and brought some concilliatory note into our somewhat billigerent conversation. I hope I have made my case on viewing differentiation in 1 variable as division in a ring of functions, and I hope you understand that it doesn’t involve any fudging or hand-waving. To the contrary, it’s more earnest than limits (and simpler at that:-). To me,doing mathematics honestly doesn’t mean doing it in greater generality, it means using the appropriate tools to solve a problem at hand. To me it’s a good mathematical taste to solve elementary problems by elementary means. That’s the bone that I have with the standard approach to elementary calculus, it uses power tools where the simple tools suffice. Using the power tools and generalities indiscriminately more often obfuscates rather than clarifies the situation. One of the most egregious exmples is a popular use of the mean value theorem to prove the fundamental theorem of calculus, while it’s clear that one has nothing to do with the other, and a more straight-forward approach (based on positivity of the integral) works just fine.
You are wrong that one needs limits to deal with removable singularity. Again, “fully rigorous” doesn’t mean “excessively general” the explicit estimates + the Archmedes principle suffice when we demand the explicit estimates (like Lipschiz or any modulus of continuity) from the quotient.
Speaking about non-standard analysis, it’s not at all “a whole other kettle of fish,” as you put it, it’s just a sleek way to sweep the limits under the rug by using the utra-filter technology, and it’s not difficult to see through these tricks. Ultra-filters are very removed from reality, nobody ever constructed an explicit example of a nontrivial ultrafilter, and nobody ever will, it’s unconstructive and uncostructible, a sheer mathematical fantasy. By the way, the feature of the nonstandard approach
to calculus that its advocates boast about the most is the automatic continuity of a functions differentiable on a hyperreal interval. Well, why then not use the uniform differentiability that gives the same result (for a real or a rational or whatever interval) much cheaper and save all the sweat of learning hyperreals? You can still learn them if you love them, but they they don’t provide the simplest approach to elementary calculus by a long shot.
About multivariable derivatifes: the uniform estimates work fine, just replace with a linear map and the absolute value with a norm of vectors. It’s coordinate-free.
with a linear map and the absolute value with a norm of vectors. It’s coordinate-free.
Let me address John’s objections first. Let’s take a look at division by in the ring of polynomials on
in the ring of polynomials on  . Only the polynomials that vanish at 0 are divisible by
. Only the polynomials that vanish at 0 are divisible by  . But for any polynomial
. But for any polynomial 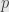
 is divisible by
is divisible by  (long division) and we can write
(long division) and we can write 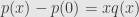 and define
and define 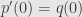 . Likewise, not all Lipschitz functions on
. Likewise, not all Lipschitz functions on  are divisible by
are divisible by  , but some are. If
, but some are. If  divides
divides  we can write
we can write 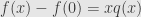 and define
and define 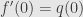 . See the analogy? Substitute “continuous” for “Lipschitz”, and you will get classical differentiability. Instead of Lipschiz we can use any modulus of continuity (and any continuous function has one), for example,
. See the analogy? Substitute “continuous” for “Lipschitz”, and you will get classical differentiability. Instead of Lipschiz we can use any modulus of continuity (and any continuous function has one), for example, 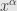 . So, by using this algebraic approach, we are not missing any of the classical theory. Differentiability of
. So, by using this algebraic approach, we are not missing any of the classical theory. Differentiability of 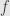 at
at  is the same as divisibility of
is the same as divisibility of  by
by  , in this respect differentiable functions behave like polynomials. Now, all polynomials are Lipschitz (long division again), so the Lipschitz theory is simply a generalization of the polynomial theory. See how it flows, from special to general, from examples to definitions, from observations and calculations to theorems, all the way using the tools familiar to the students? Isn’t it better than clubbering them with the abstractions they are not ready for (for every epsilon there is delta such that for every x… and what “is” is, as Bill Clinton had put it aptly?) or invoking “intuition” to describe the general notion of continuity that is so terribly remote from intuition?
, in this respect differentiable functions behave like polynomials. Now, all polynomials are Lipschitz (long division again), so the Lipschitz theory is simply a generalization of the polynomial theory. See how it flows, from special to general, from examples to definitions, from observations and calculations to theorems, all the way using the tools familiar to the students? Isn’t it better than clubbering them with the abstractions they are not ready for (for every epsilon there is delta such that for every x… and what “is” is, as Bill Clinton had put it aptly?) or invoking “intuition” to describe the general notion of continuity that is so terribly remote from intuition?
But onward with the Lipschitz theory! Take a look at the factoring: . Here
. Here 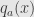 is Lipschitz, in particular,
is Lipschitz, in particular, 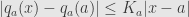 with some constant
with some constant 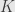 . Let’s plug this inequality in and use our definition
. Let’s plug this inequality in and use our definition 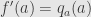 . We get the estimate,
. We get the estimate, 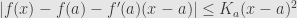 . Now, the dependence of
. Now, the dependence of 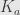 on
on  may be rather nasty in general, and in the most favorable (and practical) situation, when
may be rather nasty in general, and in the most favorable (and practical) situation, when  is Lipschitz,
is Lipschitz, 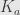 will be bounded, and the estimate will be uniform:
will be bounded, and the estimate will be uniform:  . We can take this estimate as the definition of the uniform Lipschitz differentiability (ULD), and see immediately (by dividing the inequality by
. We can take this estimate as the definition of the uniform Lipschitz differentiability (ULD), and see immediately (by dividing the inequality by  , switching
, switching  and
and  and comparing these inequalities) that
and comparing these inequalities) that 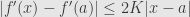 , i.e.,
, i.e.,  is Lipschitz. See the analogy with the polynomials? The derivatives of polynomials are polynomials, the derivatives of ULD functions are Lipschiz. The inequality defining ULD can be arrived at when we examine polynomials and try to understand why a tangent looks like a tangent and why polynomials with positive derivatives are increasing. This monotonicity theorem takes the center stage in the uniform approac to calculus. Again, the flow of material is from examples to definitions, from special to general, from problems to theorems. It reflects better how the mathematical notions are discovered and evolve naturally. Now, instead of Lipschitz we can use any modulus of continuity, and recapture uniform differentiability in the classical sense, see a nice article by Mark Bridger at
is Lipschitz. See the analogy with the polynomials? The derivatives of polynomials are polynomials, the derivatives of ULD functions are Lipschiz. The inequality defining ULD can be arrived at when we examine polynomials and try to understand why a tangent looks like a tangent and why polynomials with positive derivatives are increasing. This monotonicity theorem takes the center stage in the uniform approac to calculus. Again, the flow of material is from examples to definitions, from special to general, from problems to theorems. It reflects better how the mathematical notions are discovered and evolve naturally. Now, instead of Lipschitz we can use any modulus of continuity, and recapture uniform differentiability in the classical sense, see a nice article by Mark Bridger at
http://www.math.neu.edu/~bridger/LBC/lbcswp.pdf for a nice exposition. As he says in this article, lots of theorems proofs in anlysis start with: “the function is continuous, therefore it’s uniformly continuous,” so, why not start with uniform continuity and differentiafility right off the bat?
Now, John, for your question “on what domain?” When we work with uniform estimates the question of domain becomes immaterial, since any uniformly continuous, or Lipschiz function automatically extends to the completion of its original domain. We can start with rational numbers, or algebraic numbers, or any other dense subset of the interval, it doesn’t matter, the results will be the same.
And frankly, we don’t even need the reals in the full generality in this approach, the subtle notions of compactness and completeness play almost no role in it. About the only thing that we need is the Archimedes axiom: any number that is less than any negative number is either zero or positive.
Now, about topological and analytic considerations. I never claimed that they don’t exist, but I claim that in an introductory calculus such considerations are better handled by explicit uniform estimates. I think that dragging in the generalities and clubbering students with terminology at this stage is counterproductive. Continuity and limits can be introduced later (or in a different course of introductory analysis), and will look more natural to those who saw the uniform estimates.
What about a function that have no formula? It’s fine, it has some other description (it may be a solution to a differential equation) or properties (it may be Lipschitz, or integrable, ect.). The box is not usually totally black, otherwise we can’t say anything. How can you take a limit of a totally black box function? You can just dream about it, that’s about it. We usually have some estimates or other properties to work with.
Surely, neither naive algebraic nor uniform estimates approach work universally, but neither the classical approach breaks down too when we move to measures and other distributions, and there the algebraic and absract point of view shows us the way forward. There is nothing sacred about our definitions, they just codify the situations that we encounter when we try to solve this problem or that, the idea that there is THE DEFINITION for everythig is a fallacy. The only mesure of the value of a definition is how useful it is in solving problems.
Now about pedagogy. When you teach physics, do you start with quantum field theory or general relativity? Surely not, you start with some simple mechanics, conceptual parts of heat, electricity etc. You treat elementary problems by elementary means. You don’t drag in the advanced notions when the simple notions do the job. Why not do the same with introductory calculus? Why use complicated explanations and advanced tools when simple tools do the job and simple explanations are available? Just compare the complexity new approach that I (and other people) are suggesting with complexity of the classical analysis and see the difference. You can actually explain in all the details the new approach to a student who mastered high school algebra and geometry, with very little overhead. Can you do the same for classical approach? I seriously doubt it.
See? I’m not screaming, I wanted you to take a look and you didn’t want to see, it was you who kept screaming. What do I want? I want to shake you out of your complacency, I want you to stop hiding behind the memorized abstractions and take a fresh look at the subject you are teaching. I want you to recognize a promising idea when you see it, even if it’s an unusual one and you knee-jerk reaction is just to brush it away.
Now for you, Todd, and I’m glad you have joined our discussion and brought some concilliatory note into our somewhat billigerent conversation. I hope I have made my case on viewing differentiation in 1 variable as division in a ring of functions, and I hope you understand that it doesn’t involve any fudging or hand-waving. To the contrary, it’s more earnest than limits (and simpler at that:-). To me,doing mathematics honestly doesn’t mean doing it in greater generality, it means using the appropriate tools to solve a problem at hand. To me it’s a good mathematical taste to solve elementary problems by elementary means. That’s the bone that I have with the standard approach to elementary calculus, it uses power tools where the simple tools suffice. Using the power tools and generalities indiscriminately more often obfuscates rather than clarifies the situation. One of the most egregious exmples is a popular use of the mean value theorem to prove the fundamental theorem of calculus, while it’s clear that one has nothing to do with the other, and a more straight-forward approach (based on positivity of the integral) works just fine.
You are wrong that one needs limits to deal with removable singularity. Again, “fully rigorous” doesn’t mean “excessively general” the explicit estimates + the Archmedes principle suffice when we demand the explicit estimates (like Lipschiz or any modulus of continuity) from the quotient.
Speaking about non-standard analysis, it’s not at all “a whole other kettle of fish,” as you put it, it’s just a sleek way to sweep the limits under the rug by using the utra-filter technology, and it’s not difficult to see through these tricks. Ultra-filters are very removed from reality, nobody ever constructed an explicit example of a nontrivial ultrafilter, and nobody ever will, it’s unconstructive and uncostructible, a sheer mathematical fantasy. By the way, the feature of the nonstandard approach
to calculus that its advocates boast about the most is the automatic continuity of a functions differentiable on a hyperreal interval. Well, why then not use the uniform differentiability that gives the same result (for a real or a rational or whatever interval) much cheaper and save all the sweat of learning hyperreals? You can still learn them if you love them, but they they don’t provide the simplest approach to elementary calculus by a long shot.
About multivariable derivatifes: the uniform estimates work fine, just replace with a linear map and the absolute value with a norm of vectors. It’s coordinate-free.
with a linear map and the absolute value with a norm of vectors. It’s coordinate-free.
Oops! I thought I could go back to the comment window and correct a typo, but it didn’t work, sorry. You can disregard comment #32 or remove it, as the owner of the blog.
Yes, I see the analogy. I’ve acknowledged the analogy from the beginning, but it’s an analogy, and one which, I feel, does students more harm than good in the long run if not handled delicately.
You say I didn’t look, and I keep assuring you that I have looked. You’re welcome to your own opinion, but I just don’t share it. Somehow that doesn’t seem to satisfy you.
I didn’t say you didn’t look, I said you didn’t want to see. Maybe you wanted to see, but could not. Most likely you have just a different mind-set and prefer to start with lofty definitions and mighty theorems instead of special examples and problems that help you see a glimpse of a general theory, and that’s how most of the new mathematics originates. It’s a pity that you see it as just an analogy and not see it as a legitimate way of looking at the subject. Even if it’s just an analogy, you are probably aware how important analogies are in discovery. Taking some decisive property (like the inequality characterizing ULD) that you use in proving the monotonicity theorem for polynomials and promoting it to a definition is a true example of how mathematics is done. Let’s not overestimate the rigor, it comes last, while the guess comes first. As George Polya puts it, logic is the lady at the exit of the supermarket that checks the price of the items in the basket whose content she did not choose.
I didn’t say it wasn’t legitimate. I said that I find it to cause problems further down the line. Stop putting words in my mouth.
I’m sorry, I didn’t mean to put words into your mouth. Speaking of problems, Hermann Karcher from Bonn University taught calculus via uniform estimates to science and engineering students, and had some anecdotal evidence that they had less trobles with more advanced subjects that use calculus, such as numercal analysis. So the evidence is somewhat to the contrary to what you say. Of course this evidence is not very strong, but still… Unless we try new things we will never know if they work better. My hunch is that the new approach will be better for people who take more active approach to learning mathematics, who enjoy serious problem solving.
Michael, if I were to summarize what I think you were saying earlier, it’s simply that a continuous function f has a derivative at a if there is a continuous function g such that f(x) – f(a) = g(x)(x – a) [cf. comments 25, 28]. But how is that very different from using limits? You agree, don’t you, that the notions of continuity and limit are closely linked?
Todd, I agree that limits and continuity of functions are related, and in fact reducible to each other in the following sense. if and only if we can make
if and only if we can make 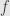 continuous at
continuous at  by setting
by setting  . So we can define continuiy first, and use it to define limits, in fact E.Chech (ever heard of Stone-Chech compactification or Chech cohomology?) did just that when he taught introductory analysis at U.Chicago, and it worked fine. From that duo, continuity was introduced first, is more important and is easier to understand, since we don’t have to worry what the
. So we can define continuiy first, and use it to define limits, in fact E.Chech (ever heard of Stone-Chech compactification or Chech cohomology?) did just that when he taught introductory analysis at U.Chicago, and it worked fine. From that duo, continuity was introduced first, is more important and is easier to understand, since we don’t have to worry what the 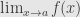 is, we want it to be
is, we want it to be 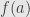 , so the defition of f being continuous at a becomes “for every e>0 there is d>0 such that |f(x)-f(a)|<e as soon as |x-a|<d”. In topology continuity is defined in term of open set (see John’s blog), and limits hardly ever mentioned. I’d say that of the duo, continuity is one of “bread-and-butter” notions, while limit the limit of a function is just a convenient technicality.
, so the defition of f being continuous at a becomes “for every e>0 there is d>0 such that |f(x)-f(a)|<e as soon as |x-a|<d”. In topology continuity is defined in term of open set (see John’s blog), and limits hardly ever mentioned. I’d say that of the duo, continuity is one of “bread-and-butter” notions, while limit the limit of a function is just a convenient technicality.
From the practical perspective, these definitions, as well as the definition of the limit of a sequence are problematic. They don’t ansewr the question “how small d we should take for a given e?” or, for sequences, “how big N should be?” and these questions are important when we turn from mathematical theorizing to practical calculations. That’s where the modulus of continuity comes in.
Also it is usually of interest whether we can take d that will be good for e and any a in a certain range of values (uniform continuity). In classical approach they say that f is continuous if it is continuous everywhere it is defined,
and then they prove the theorem that says that a function f, continuous on a closed interval [A,B], is uniformly continuous. It is a very subtle and difficult theorem, and a proof is usually relegated to an introductory analysis course. But this theorem is very important for calculus, it is used in constructing the Riemann-like integral for continuous functions. This leaves a wide gap in
understanding for poor calculus students, and it’s not the only mystery that they have to deal with.
To alleviate this problem, some people dispose with the pointwise notions of continuity and differentiability altogether and use the uniform notions instead (see the links in my comments #19 and #33). Some go even further and deal mostly with Lipschitz functions, at least at the beginning, see a text in German (with an English summary and an essay in the last 14 pages) by Hermann Karcher at http://www.math.uni-bonn.de/people/karcher/MatheI_WS/ShellSkript.pdf
Now, you implied that viewing differentiatibility of f at a as divisibility of f(x)-f(a) by x-a in the class of continuous functions is not that different from that standard definition. That is true, of course, it is another way of looking at it. But you should not say “just another way,” different ways of looking at the same thing suggest different generalizations and/or modifications, they also contribute to a depper understanding of the subject and put more tools in our hands. Consider the chain rule, for example. The division point of view makes it almost obvious, and makes its proof simple, while the proof that uses limits is more cumbersome.
Finally, I suspect that John is already tired of us (especially me) squatting on his blog and want us to take our conversation elsewhere, right, John?
[…] we do have a higher-dimensional analogue for the chain rule. If we have a function defined on some open region and another function defined on a region […]
Pingback by The Chain Rule « The Unapologetic Mathematician | October 7, 2009 |
[…] The Radon-Nikodym Chain Rule Today we take the Radon-Nikodym derivative and prove that it satisfies an analogue of the chain rule. […]
Pingback by The Radon-Nikodym Chain Rule « The Unapologetic Mathematician | July 12, 2010 |
[…] should note, here, how this recalls the Newtonian notation for the chain rule, where we wrote . Of course, multiplication is changed into composition of linear maps, but that […]
Pingback by Functoriality of the Derivative « The Unapologetic Mathematician | April 7, 2011 |