The Meaning of the SVD
We spent a lot of time yesterday working out how to write down the singular value decomposition of a transformation  , writing
, writing
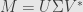
where 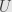 and
and 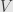 are unitary transformations on
are unitary transformations on 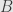 and
and 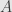 , respectively, and
, respectively, and 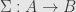 is a “diagonal” transformation, in the sense that its matrix looks like
is a “diagonal” transformation, in the sense that its matrix looks like

where 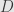 really is a nonsingular diagonal matrix.
really is a nonsingular diagonal matrix.
So what’s it good for?
Well, it’s a very concrete representation of the first isomorphism theorem. Every transformation is decomposed into a projection, an isomorphism, and an inclusion. But here the projection and the inclusion are built up into unitary transformations (as we verified is always possible), and the isomorphism is the part of  .
.
Incidentally, this means that we can read off the rank of 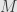 from the number of rows in , while the nullity is the number of zero columns in .
from the number of rows in , while the nullity is the number of zero columns in .
More heuristically, this is saying we can break any transformation into three parts. First, 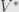 picks out an orthonormal basis of “canonical input vectors”. Then handles the actual transformation, scaling the components in these directions, or killing them off entirely (for the zero columns). Finally, takes us out of the orthonormal basis of “canonical output vectors”. It tells us that if we’re allowed to pick the input and output bases separately, we kill off one subspace (the kernel) and can diagonalize the action on the remaining subspace.
picks out an orthonormal basis of “canonical input vectors”. Then handles the actual transformation, scaling the components in these directions, or killing them off entirely (for the zero columns). Finally, takes us out of the orthonormal basis of “canonical output vectors”. It tells us that if we’re allowed to pick the input and output bases separately, we kill off one subspace (the kernel) and can diagonalize the action on the remaining subspace.
The SVD also comes in handy for solving systems of linear equations. Let’s say we have a system written down as the matrix equation

where is the matrix of the system. If 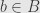 is the zero vector we have a homogeneous system, and otherwise we have an inhomogeneous system. So let’s use the singular value decomposition for :
is the zero vector we have a homogeneous system, and otherwise we have an inhomogeneous system. So let’s use the singular value decomposition for :

and then we find

So we can check ourselves by calculating  . If this extends into the zero rows of there’s no possible way to satisfy the equation. That is, we can quickly see if the system is unsolvable. On the other hand, if lies completely within the nonzero rows of , it’s straightforward to solve this equation. We first write down the new transformation
. If this extends into the zero rows of there’s no possible way to satisfy the equation. That is, we can quickly see if the system is unsolvable. On the other hand, if lies completely within the nonzero rows of , it’s straightforward to solve this equation. We first write down the new transformation

where it’s not quite apparent from this block form, but we’ve also taken a transpose. That is, there are as many columns in  as there are rows in , and vice versa. The upshot is that
as there are rows in , and vice versa. The upshot is that 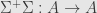 is a transformation which kills off the same kernel as does, but is otherwise the identity. Thus we can proceed
is a transformation which kills off the same kernel as does, but is otherwise the identity. Thus we can proceed
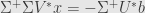
This “undoes” the scaling from . We can also replace the lower rows of  with variables, since applying will kill them off anyway. Finally, we find
with variables, since applying will kill them off anyway. Finally, we find

and, actually, a whole family of solutions for the variables we could introduce in the previous step. But this will at least give one solution, and then all the others differ from this one by a vector in 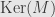 , as usual.
, as usual.
August 18, 2009 -
Posted by John Armstrong |
Algebra, Linear Algebra
No comments yet.


Leave a comment