Reduced Row Echelon Form
Let’s take row echelon form and push it a little further into a form that is unique: reduced row echelon form.
When we were doing Gaussian elimination we saved some steps by leaving pivoted rows alone. This was fine for the purposes of solving equations, where the point is just to eliminate progressively more and more variables in each equation. We also saved steps by leaving the pivots as whatever values they started with. Both of these led to a lot of variation in the possibilities for row echelon forms. We’ll tweak the method of Gaussian elimination to give a new algorithm called “Gauss-Jordan elimination”, which will take more steps but will remedy these problems.
First of all, when we pick a pivot and swap it into place, we scale that row by the inverse of the pivot value. This will set the pivot value itself to 
Let’s see what this looks like in terms of our usual example:
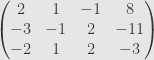
We use the 

Next, we clear out the first column with shears. Note that the shear value is now just the negative of the entry in the first column.
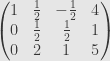
So far it’s almost the same as before, except for normalizing the pivot. But now when we choose the 


and use shears to clear the column above and below this pivot

Now the only choice for a pivot in the third column is 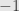

This matrix is in reduced row echelon form, and I say that it is unique. Indeed, we are not allowed to alter the basis of the input space (since that would involve elementary column operations), so we can view this as a process of creating a basis for the output space in terms of the given basis of the input space.
What we do is walk down the input basis, vector by vector. At each step, we ask if the image of this basis vector is linearly independent of the images of those that came before. If so, this image is a new basis vector. If not, then we can write the image (uniquely) in terms of the output basis vectors we’ve already written down. In our example above, each of the first three input basis vectors gives a new output basis vector, and the image of the last input basis vector can be written as the column vector in the last column.
The only possibility of nonuniqueness is if we run out of input basis vectors before spanning the output space. But in that case the last rows of the matrix will consist of all zeroes anyway, and so it doesn’t matter what output basis vectors we choose for those rows! And so the reduced row echelon form of the matrix is uniquely determined by the input basis we started with.
8 Comments »
Leave a comment
RSS Feeds


[…] Linear Group Okay, so we can use elementary row operations to put any matrix into its (unique) reduced row echelon form. As we stated last time, this consists of building up a basis for the image of the transformation […]
Pingback by Elementary Matrices Generate the General Linear Group « The Unapologetic Mathematician | September 4, 2009 |
Do we result in the same matrix in reduced row echelon form for A^T (that is A transposed)? Will it have the same number of non-zero rows?
Well, you obviously can’t get the same matrix, because the reduced row echelon form must be the same shape as the original matrix. In the example above, the reduced row echelon form of would be a
would be a  matrix, not a
matrix, not a  matrix?
matrix?
So could the reduced row echelon form of be the transpose of the reduced row echelon form of
be the transpose of the reduced row echelon form of 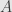 ? Well, clearly this is impossible as well. Again, looking at the example above, the transpose of the reduced row echelon form is the matrix
? Well, clearly this is impossible as well. Again, looking at the example above, the transpose of the reduced row echelon form is the matrix
which is most definitely not the reduced row echelon form of anything.
Now, what you could do is define something like the “reduced column echelon form”, replacing elementary row operations everywhere with elementary column operations. Then it would be the case that the reduced row echelon form of is the transpose of the reduced column echelon form of
is the transpose of the reduced column echelon form of 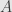 .
.
Hi,
I am looking at the construction of a holomorphic atlas on a Grassmannian of a complex vector space. Essentially this involves associating a unique k x (n-k) matrix with a k x n matrix of rank k. Books seem to assumed that the k x n matrix can always be transformed to reduced row echelon form(by Gauss Jordan Elimination?) by premultiplication by a non-singular k x k matrix (presumably corresponding to elementary row operations).
Is this always true and is the transforming matrix always non-singular? (Necessary if the result represents the same k-plane). If the k x n matrix is of rank k, does this ensure that the transformed matrix starts with the k x k identity matrix? There are perfectly good proofs that you can transform the k x n matrix in this way to have a k x k minor equal to the identity but to change this to the RRE form would involve column operations which would correspond to a change of basis in the intial space.
Yes, that’s exactly the point. The elementary row operations correspond to elementary matrices, which are nonsingular (unless you try to “scale” a row by zero). The result may not start with the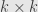 identity matrix unless you also allow elementary column operations. For instance, the matrix
identity matrix unless you also allow elementary column operations. For instance, the matrix
Is in reduced row echelon form, and has rank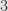 , but does not start with the
, but does not start with the  identity matrix.
identity matrix.
Thank you for the response and confirming my suspicion that a change of basis would be required.
Actually, I do not think that this change of basis is necessary to construct a chart on a Grassmannian as you can just pick out the k x (n-k) minor to determine the coordinate without needing the representative to be in the form (I|A).
[…] is (generically) dimensional. Indeed, we could use Gauss-Jordan elimination to put the system into reduced row echelon form, and (usually) find the resulting matrix starting with an identity matrix, […]
Pingback by The Implicit Function Theorem I « The Unapologetic Mathematician | November 19, 2009 |
Good website for math