Roots of Polynomials II
This one might have to suffice for two days. The movers are almost done loading the truck here in New Orleans, and I’ll be taking today and tomorrow to drive to Maryland.
We can actually tease out more information from the factorization we constructed yesterday. Bur first we need a little definition.
Remember that when we set up the algebra of polynomials we noted that the coefficients have to be all zero after some finite number of them. Thus there must be a greatest nonzero coefficient 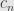
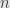

So, armed with this information, look at how we constructed the factorization 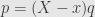

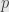



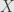


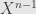
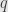
So what does this gain us? Well, each time we find a root we can factor out a term like 
A nonzero constant polynomial 

A linear polynomial 

Now let’s assume that our statement is true for all polynomials of degree 

A nice little corollary of this is that if our base field 
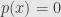
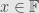

Just to be clear, though, let’s look at this one counterexample. Think about the field 


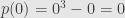
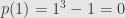

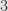
Roots of Polynomials I
When we consider a polynomial as a function, we’re particularly interested in those field elements
One easy way to get this to happen is for 

The interesting thing is that this is the only way for a root to occur, other than to have the zero polynomial. Let’s say we have the polynomial
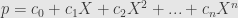
and let’s also say we’ve got a root

This is not just a field element — it’s the zero polynomial! So we can subtract it from

Now for any 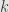

to factor out
Polynomials as Functions
When I set up the algebra of polynomials I was careful to specify that the element
We’ve got the algebra of polynomials ![\mathbb{F}[X]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BF%7D%5BX%5D&bg=e6e6e6&fg=333333&s=0&c=20201002)
![\mathrm{ev}:\mathbb{F}[X]\times\mathbb{F}\rightarrow\mathbb{F}](https://s0.wp.com/latex.php?latex=%5Cmathrm%7Bev%7D%3A%5Cmathbb%7BF%7D%5BX%5D%5Ctimes%5Cmathbb%7BF%7D%5Crightarrow%5Cmathbb%7BF%7D&bg=e6e6e6&fg=333333&s=0&c=20201002)

Remember here that the sum must terminate after a finite number of basis elements. Then we just stick the field element
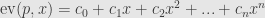
Now the superscripts on each
But it’s actually more interesting to see what happens as we fix 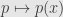

(the top coefficients here may be zero, and all higher coefficients definitely are) and a field element
=(c_0+d_0)+(c_1+d_1)x+(c_2+d_2)x^2+...+(c_n+d_n)x^n\\=c_0+d_0+c_1x+d_1x+c_2x^2+d_2x^2+...+c_nx^n+d_nx^n\\=c_0+c_1x+c_2x^2+...+c_nx^n+d_0+d_1x+d_2x^2+...+d_nx^n\\=p(x)+q(x)\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cleft%5Bp%2Bq%5Cright%5D%28x%29%3D%28c_0%2Bd_0%29%2B%28c_1%2Bd_1%29x%2B%28c_2%2Bd_2%29x%5E2%2B...%2B%28c_n%2Bd_n%29x%5En%5C%5C%3Dc_0%2Bd_0%2Bc_1x%2Bd_1x%2Bc_2x%5E2%2Bd_2x%5E2%2B...%2Bc_nx%5En%2Bd_nx%5En%5C%5C%3Dc_0%2Bc_1x%2Bc_2x%5E2%2B...%2Bc_nx%5En%2Bd_0%2Bd_1x%2Bd_2x%5E2%2B...%2Bd_nx%5En%5C%5C%3Dp%28x%29%2Bq%28x%29%5Cend%7Baligned%7D&bg=e6e6e6&fg=333333&s=0&c=20201002)
=(kc_0)+(kc_1)x+(kc_2)x^2+...+(kc_n)x^n\\=kc_0+kc_1x+kc_2x^2+...+kc_nx^n\\=k(c_0+c_1x+c_2x^2+...+c_nx^n)\\=kp(x)\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cleft%5Bkp%5Cright%5D%28x%29%3D%28kc_0%29%2B%28kc_1%29x%2B%28kc_2%29x%5E2%2B...%2B%28kc_n%29x%5En%5C%5C%3Dkc_0%2Bkc_1x%2Bkc_2x%5E2%2B...%2Bkc_nx%5En%5C%5C%3Dk%28c_0%2Bc_1x%2Bc_2x%5E2%2B...%2Bc_nx%5En%29%5C%5C%3Dkp%28x%29%5Cend%7Baligned%7D&bg=e6e6e6&fg=333333&s=0&c=20201002)
I’ll let you write out the verification that it also preserves multiplication.
In practice this “evaluation homomorphism” provides a nice way of extracting information about polynomials. And considering polynomials as functions provides another valuable slice of information. But we must still keep in mind the difference between the abstract polynomial
and the field element

Polynomials
Okay, we’re going to need some other algebraic tools before we go any further into linear algebra. Specifically, we’ll need to know a few things about the algebra of polynomials. Specifically (and diverging from the polynomials discussed earlier) we’re talking about polynomials in one variable, and with coefficients in the field we’re building our vector spaces over already.
We’ll write this algebra as 





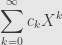
as long as there are only a finite number of nonzero terms in this sum. That is, the coefficients are all zero after some point. We customarily take 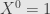
Note here that we’re not using the summation convention for polynomials, though we could in principle. Remember, an algebra is a vector space, and what we’ve said above establishes that the set 
The algebra structure can be specified by defining it on pairs of basis elements. Remember that the structure is just a bilinear multiplication, which is just a linear map from the tensor square ![\mathbb{F}[X]\otimes\mathbb{F}[X]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BF%7D%5BX%5D%5Cotimes%5Cmathbb%7BF%7D%5BX%5D&bg=e6e6e6&fg=333333&s=0&c=20201002)
Anyhow, how should we define the multiplication? Simply: 
Open Gap Thread
I’m preparing for my drive tomorrow. I’m heading down to New Orleans for the final move-out. As such, I think I’ll throw this one out to discuss the (non)existence of the math gender gap. Also, feel free to weigh in about Title IX applying to math and science departments. The latter I heard about through Jesse Johnson, so here’s a tam-tip to him.
Talk amongst yourselves.
The Inclusion-Exclusion Principle
In combinatorics we have a method of determining the cardinality of unions in terms of the sets in question and their intersection: the Inclusion–Exclusion Principle. Predictably enough, this formula is reflected in the subspaces of a vector space. We could argue directly in terms of bases, but it’s much more interesting to use the linear algebra we have at hand.
Let’s start with just two subspaces 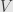

Now we consider the sum of the subspaces. Every vector in 


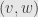


This function is always surjective, but it may fail to be injective. Specifically, if 
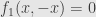
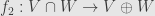

Now it’s clear that 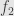
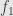
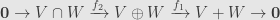
Taking the Euler characteristic we find that
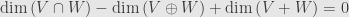
Some simple juggling turns this into
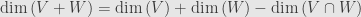
which is the inclusion-exclusion principle for two subspaces.
What about three subspaces 

defined by 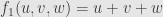

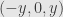


defined by 
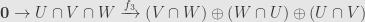
defined by 
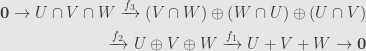
Taking the Euler characteristic and juggling again we find
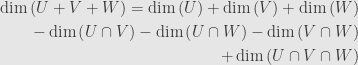
We include the dimensions of the individual subspaces, exclude the dimensions of the pairwise intersections, and include back in the dimension of the triple intersection.
For larger numbers of subspaces we can construct longer and longer exact sequences. The 
The result is that the dimension of a sum of subspaces is the alternating sum of the dimensions of the
From here it’s the work of a moment to derive the combinatorial inclusion-exclusion principle. Given a collection of sets, just construct the free vector space on each of them. These free vector spaces will have nontrivial intersections corresponding to the nonempty intersections of the sets, and we’ve got canonical basis elements floating around to work with. Then all these dimensions we’re talking about are cardinalities of various subsets of the sets we started with, and the combinatorial inclusion-exclusion principle follows. Of course, as I said before we could have proved it from the other side, but that would require a lot of messy hands-on work with bases and such.
The upshot is that the combinatorial inclusion-exclusion principle is equivalent to the statement that exact sequences of vector spaces have trivial Euler characteristic! This little formula that we teach in primary or secondary school turns out to be intimately connected with one of the fundamental tools of homological algebra and the abstract approach to linear algebra. Neat!
The Euler Characteristic of an Exact Sequence Vanishes
Naturally, one kind of linear map we’re really interested in is an isomorphism. Such a map has no kernel and no cokernel, and so its index is definitely zero. If it weren’t clear enough already, this shows that isomorphic vector spaces have the same dimension!
But remember that in abelian categories we’ve got diagrams to chase and exact sequences to play with. And these have something to say about the matters at hand.
First, remember that a linear map whose kernel vanishes looks like this in terms of exact sequences:

And one whose cokernel vanishes looks like this:

So an isomorphism is just an exact sequence like this:
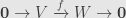
And then we have the equation

Yes, I’m writing the negative of the index here, but there’s a good reason for it.
Now what if we have a segment of an exact sequence:

Considering the map 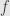

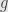



Now the rank-nullity theorem says that 

What does this mean? It says that if we look at every other term of an exact sequence and take their direct sum, the result is the same whether we look at the odd or the even terms. More explicitly, let’s say we have a long exact sequence

Then we can decompose each term as either 


which tells us that

But since direct sums add dimensions this means

And now we can just combine these sums:

Which generalizes the formula we wrote above in the case of an isomorphism. This alternating sum we call the “Euler characteristic” of a sequence, and we’ll be seeing a lot more of that sort of thing in the future. But here the major result is that for exact sequences we always get the value zero.
In fact, this amounts to a far-reaching generalization of the rank-nullity theorem. And that theorem, of course, is essential to the proof. Yet again we see this pattern of “bootstrapping” our way from a special case to a larger theorem. Despite some mathematicians being enamored of reductio ad absurdum, this induction from special to general has to be one of the most useful tools we keep running across.
The Index of a Linear Map
Today I want to talk about the index of a linear map 
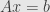
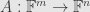
One important quantity is the dimension of the kernel of 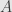
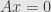
But the system is inhomogenous in general, and as such it might not have any solutions. Since every short exact sequence of vector spaces splits we can write 
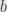
Now the condition that the system have any solutions is that the component of 
But what happens if we quotient out 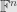


Now I’ll define the index 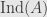
Anyhow, we’ve got this definition:

Now let’s add and subtract the dimension of the image of

Clearly the dimension of the image and the dimension of the cokernel add up to the dimension of the target space. But notice also that the rank-nullity theorem tells us that the dimension of the kernel and the dimension of the image add up to the dimension of the source space! That is, we have the equality
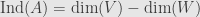
What happened here? We started with an analytic definition in terms of describing solutions to a system of equations, and we ended up with a geometric formula in terms of the dimensions of two vector spaces.
What’s more, the index doesn’t really depend much on the particulars of
Alternately, what happens when we add a new equation to a system? With a new equation the dimension of the target space goes up, and so the index goes down. One very common way for this to occur is for the dimension of the solution space to drop. This gives rise to our intuition that each new equation reduces the number of independent solutions by one, until we have exactly as many equations as variables.
The Sum of Subspaces
We know what the direct sum of two vector spaces is. That we define abstractly and without reference to the internal structure of each space. It’s sort of like the disjoint union of sets, and in fact the basis for a direct sum is the disjoint union of bases for the summands.
Let’s use universal properties to prove this! We consider the direct sum 
That is, there is a forgetful functor from 
![\mathbb{F}\left[S\right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BF%7D%5Cleft%5BS%5Cright%5D&bg=e6e6e6&fg=333333&s=0&c=20201002)
![V\cong\mathbb{F}\left[A\right]](https://s0.wp.com/latex.php?latex=V%5Ccong%5Cmathbb%7BF%7D%5Cleft%5BA%5Cright%5D&bg=e6e6e6&fg=333333&s=0&c=20201002)
Okay. So we’re really considering the direct sum ![\mathbb{F}\left[A\right]\oplus\mathbb{F}\left[B\right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BF%7D%5Cleft%5BA%5Cright%5D%5Coplus%5Cmathbb%7BF%7D%5Cleft%5BB%5Cright%5D&bg=e6e6e6&fg=333333&s=0&c=20201002)
![\mathbb{F}\left[A\uplus B\right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BF%7D%5Cleft%5BA%5Cuplus+B%5Cright%5D&bg=e6e6e6&fg=333333&s=0&c=20201002)
But not all unions of sets are disjoint. Sometimes the sets share elements, and the easiest way for this to happen is for them to both be subsets of some larger set. Then the union of the two subsets has to take this overlap into account. And since subspaces of a larger vector space may intersect nontrivially, their sum as subspaces has to take this into account.
First, here’s a definition in terms of the vectors themselves: given two subspaces 
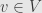
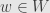

Alternatively, let’s consider the collection of all subspaces of
Now it turns out that, like the power set, this poset is actually a lattice. The meet is the intersection of subspaces, but the join isn’t their union. Indeed, the union of subspaces usually isn’t a subspace at all! What do we use instead? The sum, of course! It’s easiest to verify this with the algebraic definition of a lattice.
The lattice does have a top element (the whole space 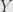
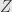



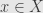

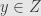


Unfortunately, the lattice isn’t distributive. I could work this out directly, but it’s easier to just notice that complements aren’t unique. Just consider three subspaces of 




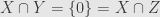

This is all well and good, but it’s starting to encroach on Todd’s turf, so I’ll back off a bit. The important bit here is that the sum behaves like a least-upper-bound.
In categorical terms, this means that it’s a product in the lattice of subspaces (considered as a category). Don’t get confused here! Direct sums are coproducts in the category
In this case, all we mean by saying this is a categorical coproduct is that we have a description of the sum of two subspaces which doesn’t refer to the elements of the subspaces at all. The sum
Unsolvable Inhomogenous Systems
We know that when an inhomogenous system has a solution, it has a whole family of them. Given a particular solution, it defines a coset of the subspace of the solutions to the associated homogenous system. And that subspace is the kernel of a certain linear map.
But must there always be a particular solution to begin with? Clearly not. When we first talked about linear systems we mentioned the example
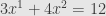
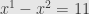

In our matrix notation, this reads
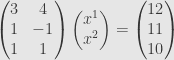
or
We saw then that this system has no solutions at all. What’s the problem? Well, we’ve got a linear map 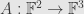

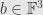

The upshot is that we can only solve the system 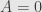
RSS Feeds

