The Gradient Vector
The most common first approach to differential calculus in more than one variable starts by defining partial derivatives and directional derivatives, as we did. But instead of defining the differential, it simply collects the partial derivatives together as the components of a vector called the gradient of 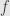

We showed that these partial derivatives are the components of the differential (when it exists), and so there should be some connection between the two concepts. And indeed there is.
As a bilinear form, our inner product defines an isomorphism from the space of displacements to its dual space. This isomorphism sends the basis vector 


and

That is, the linear functional 
So under this isomorphism the differential 
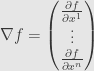
We can remove the function from this notation to write the operator 
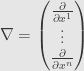
We also write the gradient vector at a given point as 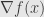


Now, under our approach the differential is more fundamental and more useful than the gradient vector. However, there is some meaning to the geometric interpretation of the gradient as a displacement vector.
First of all, let’s ask that 
=df(x;u)](https://s0.wp.com/latex.php?latex=%5Cleft%5BD_uf%5Cright%5D%28x%29%3Ddf%28x%3Bu%29&bg=e6e6e6&fg=333333&s=0&c=20201002)


=\langle\nabla f(x),u\rangle](https://s0.wp.com/latex.php?latex=%5Cleft%5BD_uf%5Cright%5D%28x%29%3D%5Clangle%5Cnabla+f%28x%29%2Cu%5Crangle&bg=e6e6e6&fg=333333&s=0&c=20201002)
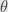
=\lVert\nabla f(x)\rVert\cos(\theta)](https://s0.wp.com/latex.php?latex=%5Cleft%5BD_uf%5Cright%5D%28x%29%3D%5ClVert%5Cnabla+f%28x%29%5CrVert%5Ccos%28%5Ctheta%29&bg=e6e6e6&fg=333333&s=0&c=20201002)
since the length of 
The cosine term has a maximum value of 
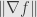
So for most purposes we’ll stick to using the differential, but in practice it’s often useful to think of the gradient vector to get some geometric intuition about what the differential means.
RSS Feeds

