I want to continue yesterday’s post with some more explicit calculations to hopefully give a bit more of the feel.
First up, let’s consider wedges of degree 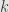 . That is, we pick vectors
. That is, we pick vectors 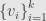 and wedge them all together (in order) to get
and wedge them all together (in order) to get 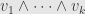 . What is its inner product with another of the same form? We calculate
. What is its inner product with another of the same form? We calculate

where in the third line we’ve rearranged the factors at the right and used the fact that  , and in the fourth line we’ve relabelled
, and in the fourth line we’ve relabelled  . This looks a lot like the calculation of a determinant. In fact, it is
. This looks a lot like the calculation of a determinant. In fact, it is 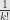 times the determinant of the matrix with entries
times the determinant of the matrix with entries  .
.
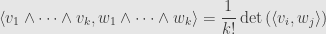
If we use the “renormalized” inner product on 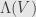 from the end of yesterday’s post, then we get an extra factor of
from the end of yesterday’s post, then we get an extra factor of  , which cancels off the and gives us exactly the determinant.
, which cancels off the and gives us exactly the determinant.
We can use the inner product to read off components of exterior algebra elements. If 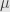 is an element of degree we write
is an element of degree we write

As an explicit example, we may take 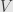 to have dimension
to have dimension 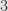 and consider an element of degree
and consider an element of degree  in
in

We call what we’re writing in the superscript to we call a “multi-index”, and sometimes we just write it as  , which in the summation convention runs over all increasing collections of indices. Correspondingly, we can just write
, which in the summation convention runs over all increasing collections of indices. Correspondingly, we can just write 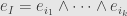 for the multi-index
for the multi-index 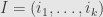 .
.
Alternatively, we could expand the wedges out in terms of tensors:

where we just think of the superscript as a collection of separate indices, all of which run from 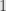 to the dimension of , with the understanding that
to the dimension of , with the understanding that 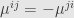 , and similarly for higher degrees; swapping two indices switches the sign of the component. All this index juggling gets distracting and confusing, but it’s sometimes necessary for explicit computations, and the physicists love it.
, and similarly for higher degrees; swapping two indices switches the sign of the component. All this index juggling gets distracting and confusing, but it’s sometimes necessary for explicit computations, and the physicists love it.
Anyway, we can use this to get back to our original definition of the determinant of a linear transformation 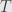 . Pick a orthonormal basis
. Pick a orthonormal basis 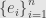 for and wedge them all together to get an element
for and wedge them all together to get an element  of top degree in . Since the space of top degree is one-dimensional, any linear transformation on it just consists of multiplying by a scalar. So we can let act on this one element we’ve cooked up, and then read off the coefficient using the inner product.
of top degree in . Since the space of top degree is one-dimensional, any linear transformation on it just consists of multiplying by a scalar. So we can let act on this one element we’ve cooked up, and then read off the coefficient using the inner product.
The linear transformation sends  to the vector
to the vector  . By functoriality, it sends to
. By functoriality, it sends to 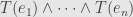 . And now we want to calculate the coefficient.
. And now we want to calculate the coefficient.

The determinant of is exactly the factor by which acting on the top degree subspace in expands any given element.
October 30, 2009
Posted by John Armstrong |
Algebra, Linear Algebra |
3 Comments

